Description
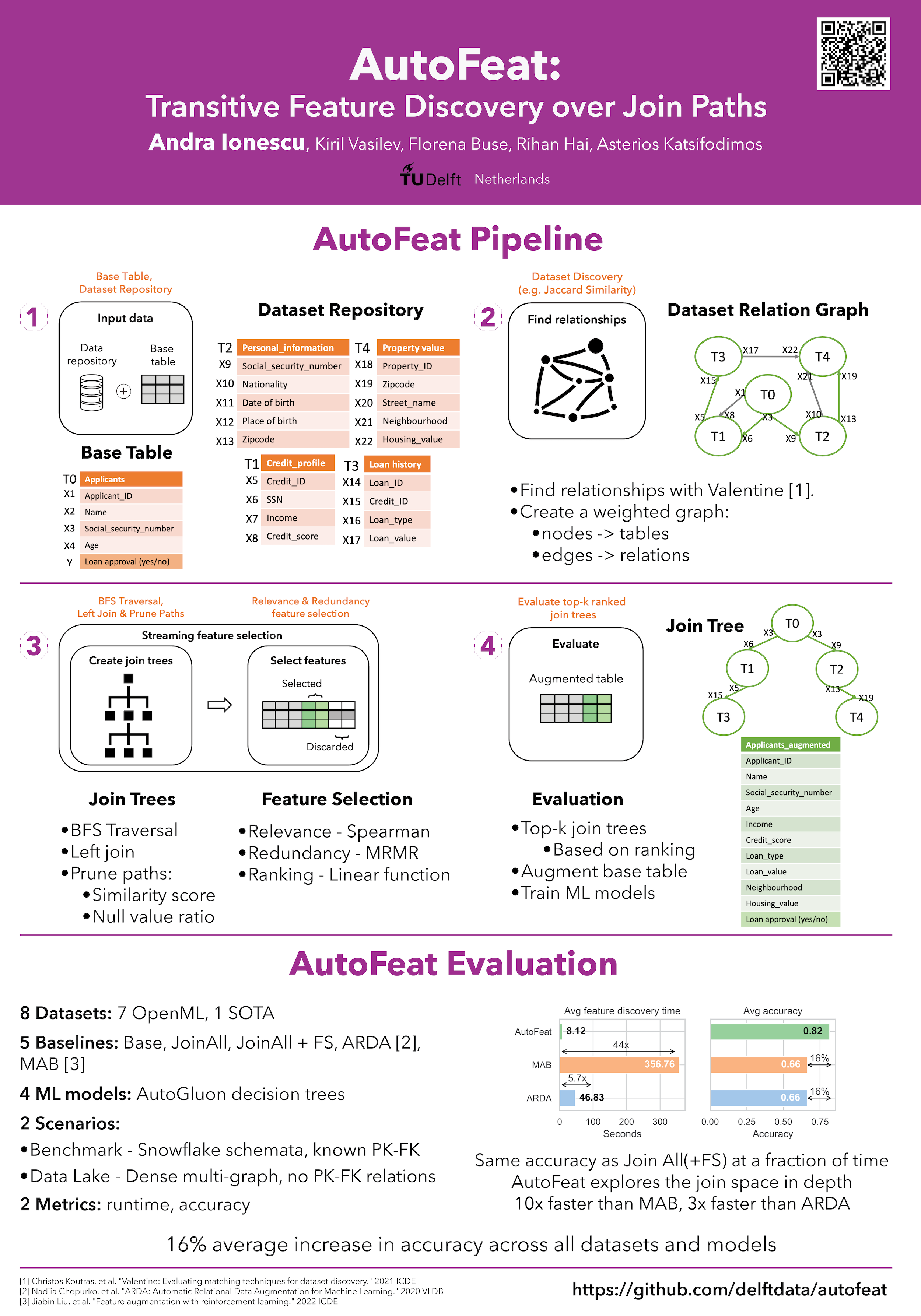
AutoFeat is an open-source automatic approach for feature discovery on tabular datasets.
Given a base table with a target variable and a repository of tabular datasets, AutoFeat helps to discover relevant features for augmentation among the tables from the data repository. The resulting augmented table will be a better training dataset for decision tree Machine Learning (ML) algorithms.
Authors

TU Delft

TU Delft

TU Delft

TU Delft

TU Delft
AutoFeat Methods
- Dataset Discovery: AutoFeat uses Valentine to discover joinable tables.
- Graph Traversal: AutoFeat uses Breadth First Search to traverse the graph of connections, which helps us manage the error propagation.
- Streaming Feature Selection: AutoFeat uses streaming feature selection to navigate the space of joinable tables and select the relevant features for augmentation.
- Relevance: AutoFeat measures the relevance of features using Pearson correlation.
- Redundancy: AutoFeat removes redundant features using Minimum Redundancy Maximum Relevance algorithm.
Datasets
| Dataset Source | # Rows | Processing strategy | # Joinable Tables | # Total Features | Links |
|---|---|---|---|---|---|
| jannis | 57581 | short_reverse_correlation | 12 | 55 | processed data |
| miniboone | 73000 | short_reverse_correlation | 15 | 51 | processed data |
| covertype | 423682 | short_reverse_correlation | 12 | 21 | processed data |
| eyemove | 7609 | short_reverse_correlation | 6 | 24 | processed data |
| credit | 1001 | short_reverse_correlation | 5 | 21 | processed data |
| bioresponse | 3435 | short_reverse_correlation | 40 | 420 | procssed data |
| steel | 1943 | short_reverse_correlation | 15 | 34 | processed data |
| school | 1775 | None | 16 | 731 | original data |
Repositories
- https://github.com/delftdata/autofeat : Main repository containing the AutoFeat source code.
- https://github.com/kirilvasilev16/PythonTableDivider : Repository containing the dataset processing strategies.
- https://github.com/delftdata/bsc_research_project_q4_2023/tree/main/autofeat_experimental_analysis : Repository containing the evaluation of relevance and redundancy methods.
AutoFeat Papers
- [Pre-print] AutoFeat: Transitive Feature Discovery over Join Paths
ICDE 2024
- Poster - companion to the paper
- Presentation - slides (pdf)
